# Text To Speech
Qolaba's platform offers a powerful Text-to-Speech (TTS) feature, allowing you to convert written text into high-quality audio.
### Accessing the Text-to-Speech Tool
To use the Text-to-Speech feature, look for the corresponding option on the left panel of the Qolaba dashboard. Clicking on it will take you to the dedicated TTS dashboard.
### Entering the Text and Selecting a Voice
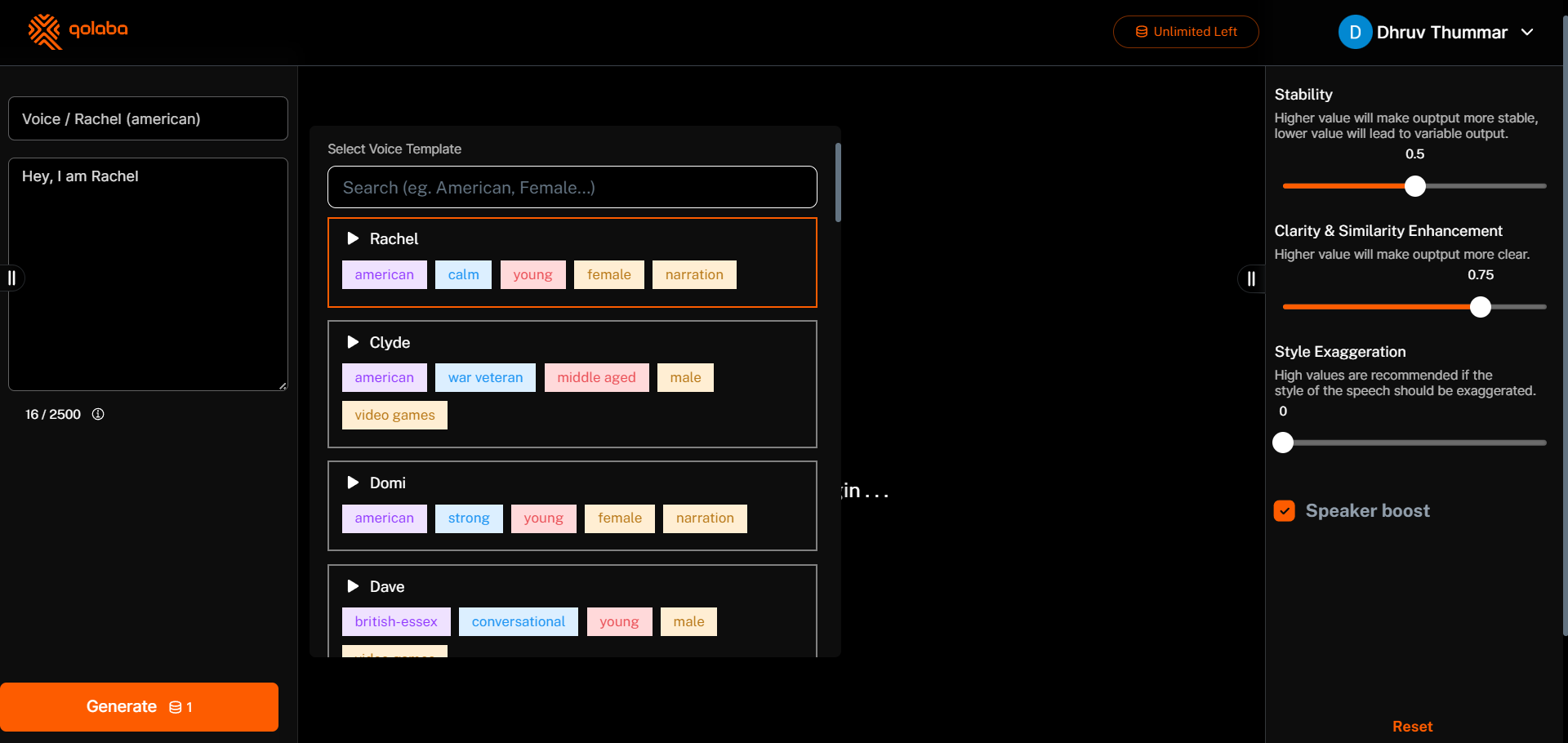
On the left side of the TTS dashboard, you'll find a text box where you can enter the content you want to convert to speech. Above the text box, you'll see an option to select the desired voice for the audio output.
### Generating the Speech Audio
Once you've entered the text and selected the voice, click the "Generate" button at the bottom of the left panel. Qolaba's TTS model will then convert your written content into an audio file.
### Adjusting the Speech Parameters
On the right side of the TTS dashboard, you'll find four options to fine-tune the generated speech:
1. **Stability**: Adjusting the Stability parameter can make the output more or less stable. Higher values result in more consistent speech, while lower values can lead to more variable output.
{% file src="" %}
Stability value 1
{% endfile %}
{% file src="" %}
Stability value 0
{% endfile %}
2. **Clarity & Similarity Enhancement**: Increasing this parameter will make the generated speech clearer and more similar to the selected voice.
{% file src="" %}
Clarity & Similarity Enhancement value 0
{% endfile %}
{% file src="" %}
Clarity & Similarity Enhancement value 1
{% endfile %}
2. **Style Exaggeration**: Higher values can exaggerate the style of the speech, making it more closely match the chosen voice. However, this may also lead to increased instability.
{% file src="" %}
Style Exaggeration value 0
{% endfile %}
{% file src="" %}
Style Exaggeration value 1
{% endfile %}
2. **Speaker Boost**: This option boosts the similarity of the synthesized speech to the selected voice, but it may slightly reduce the generation speed.
{% file src="" %}
With Speaker Boost for Rachel Voice. (The original voice could
{% endfile %}
{% file src="" %}
Without Speaker Boost for Rachel Voice
{% endfile %}
Experiment with these parameters to achieve the desired quality and characteristics for your text-to-speech output.
{% file src="" %}
Original Rachel voice
{% endfile %}
### Saving and Sharing the Audio
Once you're satisfied with the generated speech, you can save the audio file or share it directly with others using the available options.